P5318 【深基18.例3】查找文献
题目描述
小 K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小 K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有 \(n(1\le n\le10^5)\) 篇文章(编号为 \(1\) 到 \(n\))以及 \(m(1\le m\le10^6)\) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 \(X\to Y\) 表示文章 \(X\) 有参考文献 \(Y\)。不保证编号为 \(1\) 的文章没有被其他文章引用。
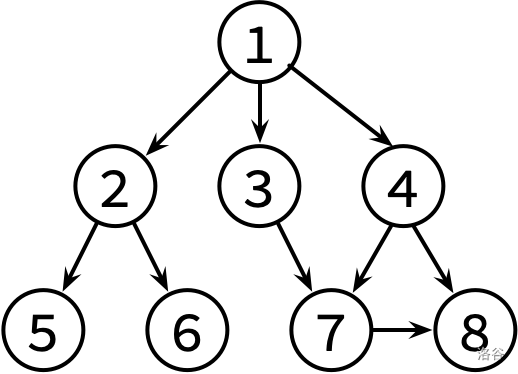
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。
输入格式
共 \(m+1\) 行,第 \(1\) 行为 \(2\) 个数,\(n\) 和 \(m\),分别表示一共有 \(n(1\le n\le10^5)\) 篇文章(编号为 \(1\) 到 \(n\))以及\(m(1\le m\le10^6)\) 条参考文献引用关系。
接下来 \(m\) 行,每行有两个整数 \(X,Y\) 表示文章 \(X\) 有参考文献 \(Y\)。
输出格式
共 \(2\) 行。
第一行为 DFS 遍历结果,第二行为 BFS 遍历结果。
输入输出样例 #1
输入 #1
输出 #1
Tip
📌 题目分析
给定数据:
要求从编号 1 的文章开始,分别进行 DFS(深度优先搜索) 和 BFS(广度优先搜索) 遍历。如果有多篇文章可以看,优先看编号较小的。
👉 本质:
👉 类型:
🧠 解题思路
1️⃣ 图的存储:为什么拒绝邻接矩阵?
题目中 \(n\) 高达 \(10^5\)。如果开一个二维数组 int graph[100005][100005] 存图,需要上百 GB 的内存,绝对会爆空间(MLE)。
面对这种稀疏图(节点多,边相对较少),我们必须使用邻接表,也就是 C++ 中的 std::vector<int> adj[N] 来存储。
2️⃣ 满足“优先看较小编号”的要求
因为我们用了 vector 存图,边读入边 push_back 的话,邻接点的顺序是毫无规律的输入顺序。
为了满足题目要求,在读入完所有边之后,我们需要用一个 for 循环,对每个节点对应的 vector 进行一次从小到大的排序(Sort)。
3️⃣ DFS 与 BFS 的核心差异
- DFS(深度优先):顺着一条引用链一直往下看,直到这篇博文没有引用、或者引用的文章全看过了,再退回到上一篇。天然适合递归实现。
- BFS(广度优先):看完当前文章所有的参考文献,再依次去看参考文献的参考文献。天然适合队列(Queue)实现。
4️⃣ 时间复杂度
排序图的时间复杂度为 \(O(M \log(\text{平均度数}))\)。 图遍历的时间复杂度为 \(O(N + M)\)。 综合下来完美控制在 \(10^6\) 运算级别,1秒内绰绰有余。
💻 C++代码
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
using namespace std;
const int MAXN = 100005;
vector<int> adj[MAXN]; // 邻接表存图
bool vis[MAXN]; // 访问标记数组
// 深度优先搜索 (递归)
void dfs(int u) {
vis[u] = true; // 标记为已访问
cout << u << " "; // 输出当前节点
// 遍历当前节点的所有邻居
for (int v : adj[u]) {
if (!vis[v]) {
dfs(v); // 只要没去过,就义无反顾地深入
}
}
}
// 广度优先搜索 (队列)
void bfs(int start) {
queue<int> q;
q.push(start);
vis[start] = true; // 入队时立刻标记
while (!q.empty()) {
int u = q.front();
q.pop();
cout << u << " ";
// 遍历当前节点的所有邻居
for (int v : adj[u]) {
if (!vis[v]) {
vis[v] = true; // ! 极其重要:入队时必须立刻标记 !
q.push(v);
}
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, m;
cin >> n >> m;
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
adj[u].push_back(v); // 建立有向边
}
// 对每个节点的邻居进行升序排序,满足“优先访问小编号”的要求
for (int i = 1; i <= n; i++) {
sort(adj[i].begin(), adj[i].end());
}
// 1. 进行 DFS
dfs(1);
cout << "\n";
// 2. 清空访问标记,准备 BFS
for (int i = 1; i <= n; i++) {
vis[i] = false;
}
// 3. 进行 BFS
bfs(1);
cout << "\n";
return 0;
}
⚠️ 易错点
❌ 1. 忘记重置标记数组
这道题要求连续跑两遍搜索。跑完 DFS 后,所有的联通节点都被标记成 true 了。如果不在 BFS 之前把 vis 数组重新清零(或使用 fill),BFS 会因为所有点都被“访问过”而什么都不输出。
❌ 2. BFS 标记时机错误(最致命!)
很多新手写 BFS 时,喜欢在节点出队(q.pop())时才将其标记为 true。
大坑: 假设节点 A 发现了节点 C,把 C 加入了队列但还没标记。紧接着节点 B 也发现了节点 C,一看 C 没被标记,又把 C 加了一次队列。这会导致同一个节点在队列里重复出现成百上千次,直接引发 Memory Limit Exceeded (MLE) 或者 Time Limit Exceeded (TLE)。
正解: 必须在节点被加入队列(q.push(v))的那一瞬间,立刻将其标记为已访问!
❌ 3. 图的连通性误解
题目说“不重复、不遗漏地看完所有他能看到的文章”。
这意味着我们只需要从 1 号节点触发即可,那些孤立的节点或者 1 号节点无法到达的分支,根本不需要去管它。不需要写外层的 for(1~n) if(!vis) 循环去搜全图。